AsaHP
AsaHP
Python PandasとJavascriptで高速にWeb開発 サンプル付き (4/5)
データ分析で用いられるPython Pandasと、Javascriptフレームワークを組み合わせて、シンプルなSPA(単一ページ)型のWeb開発を行う。この方法はWebアプリの行数を減らし、高速に開発できる。このソースは2019年に作成したものであり、現在の環境ではうまく動かない可能性がある。
機械学習の入力画面
ここから第2段階のWebアプリに移る。まず機械学習の処理を行う。以下のようなHTMLで機械学習の入力画面を作る。Bootstrapの幅12の所に入れて、form-inlineで横並びにしている。
学習結果名、モデル、使用変数を選択できるようにする。モデルと使用変数はPythonのJinja2によるループ処理を行う。使用変数は複数選択ができるようにする。
<div class="col-sm-12 border border-info rounded py-2">
<form id="result-form">
<div class="form-inline">
<div class="form-group" style="margin:10px;">
<label for="result">学習結果名:</label>
<input type="text" name="result" id="result" class="form-control form-control-sm">
</div>
</div>
<div class="form-inline">
<div class="form-group" style="margin:10px;">
<label for="model">モデル:</label>
<select name="model" id="model" class="custom-select custom-select-sm">
{% for model in models: %}
<option value="{{model}}">{{model}}</option>
{% endfor %}
</select>
</div>
<div style="margin:10px;">
<div class="form-group" style="margin:10px;">
<label for="var">使用変数:</label>
<select name="var" id="var" style="width:300px;" multiple>
{% for col in cols: %}
<option value="{{col}}" selected>{{col}}</option>
{% endfor %}
</select>
</div>
</div>
<button type="button" class="btn btn-primary" onclick="learn()" style="margin:10px;">学習</button>
</div>
</form>
</div>
Python Jinja2の指定は以下のようになる。
@app.route('/')
def index():
cols = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
models = ['パーセプトロン', 'ロジスティック回帰', 'ランダムフォレスト']
return render_template('index.html', cols=cols, models=models)
このままだと複数選択部分の見栄えが悪いので、Multiple SelectというjQueryのプラグインを使う。似たようなツールが幾つかあるが、以下のWebページのツールである。
まずHTMLのhead部分に以下の記述を追加する。これはCDNを使う場合で、ダウンロードする場合はstaticフォルダに入れる。
<link href="https://unpkg.com/multiple-select@1.5.0/dist/multiple-select.min.css" rel="stylesheet"> <script src="https://unpkg.com/multiple-select@1.5.0/dist/multiple-select.min.js"></script>
Javascriptに以下の記述を追加すれば、Multiple Selectが使えるようになる。$(function()…)の部分は、jQueryによる画面ロード時の動作指定である。#varでHTMLにある使用変数を指定している。
$(function() {
$('#var').multipleSelect();
})
残念ながらMultiple SelectはBootstrapに対応していない。form-inlineで横並びにする分には特に問題なさそうだが、縦並びだとうまく表示できない場合がある。
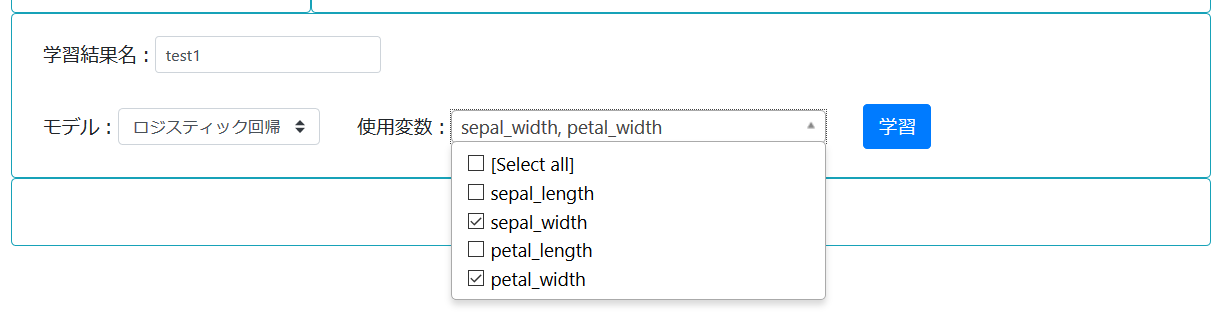
入力画面は以下のようになる。

Multiple Selectで選択すると以下のようになる。
最後に学習ボタンが押された時の処理を追加する。Javascriptのコードは以下のようになる。
function learn() {
$.post('/learn',$('#result-form').serialize())
.fail(function(ret) {
alert('学習に失敗しました');
})
.done(function(ret) {
…
});
}
機械学習の処理
ここからPythonによる機械学習の処理を作成する。まずrequestを使って入力画面の情報を受け取る。学習結果を格納するために、学習結果名のディレクトリをresultの下に作成しておく。df_srcに元データを読み込む。
@app.route('/learn', methods=['POST'])
def learn():
result = request.form['result']
model_name = request.form['model']
vars = request.form.getlist('var')
os.mkdir('result/%s' % result)
df_src = pd.read_csv('src/iris.csv', skiprows=1)
…
次にscikit-learnを使った機械学習による分類を行う。今回の趣旨から外れるため、機械学習については簡単な説明に留める。詳細を知りたい場合は以下の本などを読んで欲しい。
[第2版]Python 機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)
以下の処理では、説明変数Xと目的変数yの取得、学習データとテストデータの分離(train_test_split)、Xの正規化(StandardScaler)、モデルの選択(model)、モデルによる学習と予測を行っている。map関数により種別名を数値に変換している。最終的に学習データ・テストデータの正解率(acc_train・acc_test)と、混合行列(confmat)を作成する。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import Perceptron
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
…
src = df_src.iloc[:, range(4)].values
X = df_src.loc[:, vars].values
name_mapping = {'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2}
y = df_src.name.map(name_mapping).values
src_train, src_test, X_train, X_test, y_train, y_test = train_test_split(
src, X, y, test_size=0.3, random_state=1, stratify=y)
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
if model_name == 'パーセプトロン':
model = Perceptron(random_state=1)
elif model_name == 'ロジスティック回帰':
model = LogisticRegression(random_state=1)
elif model_name == 'ランダムフォレスト':
model = RandomForestClassifier(random_state=1)
model.fit(X_train_std, y_train)
y_pred_train = model.predict(X_train_std)
y_pred_test = model.predict(X_test_std)
acc_train = accuracy_score(y_train, y_pred_train)
acc_test = accuracy_score(y_test, y_pred_test)
confmat = [confusion_matrix(y_true=y_train, y_pred=y_pred_train),
confusion_matrix(y_true=y_test, y_pred=y_pred_test)]
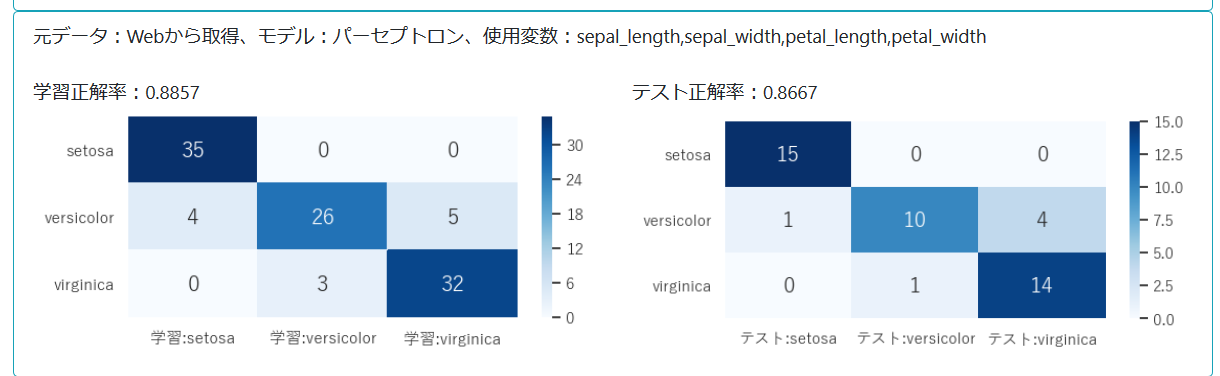
正解率と混合行列は分類問題で使用される性能の指標である。正解率は、正しい予測の合計を予測の総数で割ったものである。混合行列は、実際の分類と予測された分類の数を並べた行列であり、以下のような形式になる。
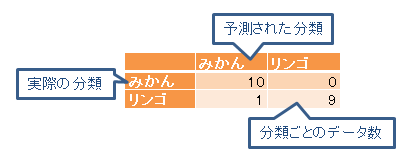
機械学習の結果ファイル保存
機械学習の結果をファイルに保存する。まず、混合行列によるヒートマップを作成する。学習・テストごとにループ処理を行い、2つの画像ファイルを作成する。これをresult/<学習結果名>のディレクトリに保存する。sns.set(font…)の部分はWindowsにおける設定であり、OSなどの環境により変える必要がある。
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
sns.set(font='Yu Gothic')
…
img_files = ['train.png', 'test.png']
titles = ['学習', 'テスト']
for i in range(0, 2):
df_res = pd.DataFrame(confmat[i])
df_res.index = ['setosa', 'versicolor', 'virginica']
df_res.columns = [titles[i] + ':setosa', titles[i] + ':versicolor', titles[i] + ':virginica']
plt.figure(figsize=(6, 2.5))
sns.heatmap(df_res, cmap='Blues', annot=True, annot_kws={'size': 15})
plt.savefig('result/' + result + '/' + img_files[i], bbox_inches='tight', pad_inches=0.1)
plt.close('all')
ヒートマップの画像ファイルは以下のようになる。
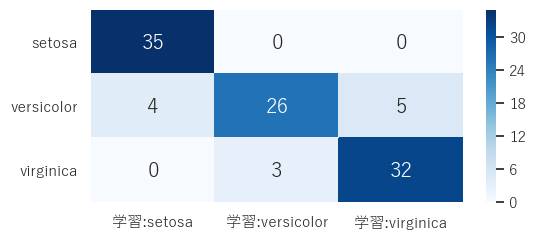
次に、機械学習の結果をCSVファイルにまとめる。ここでもPandasの機能を多用する。
コメントの部分を作成する。元データからコメントを取り、正解率、モデル名、使用変数を追加してデータフレームにまとめる。これをresult/<学習結果名>のディレクトリに保存する。
df_result_comment = df_src_comment.copy()
df_result_comment.columns = ['src']
df_result_comment['train_acc'] = acc_train
df_result_comment['test_acc'] = acc_test
df_result_comment['model'] = model_name
df_result_comment['var'] = ','.join(vars)
df_result_comment.to_csv('result/' + result + '/result.csv', index=False, encoding='CP932')
学習データの説明変数でデータフレームを作る。実際の種別名の列(y_train)と予測した種別名の列(y_pred_train)を追加する。map(lambda…)の部分で、数値を種別名に戻している。実際の種別名と予測した種別名をまとめてname列に入れる。type列に'学習'と入れる。
y_to_name = ['setosa', 'versicolor', 'virginica']
df_result_train = pd.DataFrame(src_train)
df_result_train['y_train'] = list(map(lambda y: y_to_name[y], y_train))
df_result_train['y_pred_train'] = list(map(lambda y: y_to_name[y], y_pred_train))
df_result_train['name'] = df_result_train['y_train'] + '-' + df_result_train['y_pred_train']
df_result_train['type'] = '学習'
テストデータに対しても同じ処理を行う。学習・テストデータをdf_resultという1つのデータフレームにまとめる。この際に説明変数の列(0〜3)と、name・typeの列(6・7)だけを抽出する。これらをname列とtype列でソートした後に、result/<学習結果名>ディレクトリにあるファイルに追記する。
df_result_test = pd.DataFrame(src_test)
df_result_test['y_test'] = list(map(lambda y: y_to_name[y], y_test))
df_result_test['y_pred_test'] = list(map(lambda y: y_to_name[y], y_pred_test))
df_result_test['name'] = df_result_test['y_test'] + '-' + df_result_test['y_pred_test']
df_result_test['type'] = 'テスト'
df_result = df_result_train.iloc[:, [0, 1, 2, 3, 6, 7]]
df_result = df_result.append(df_result_test.iloc[:, [0, 1, 2, 3, 6, 7]])
df_result.columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'name', 'type']
df_result = df_result.sort_values(['name', 'type'], ascending=[True, False])
df_result.to_csv('result/' + result + '/result.csv', index=False, mode='a', encoding='CP932')
最後に成功を示す戻り値と、学習結果名と、拡張したコメント部分をJSONで返却する。
return '{"ret":"ok","result":' + json.dumps(result) + ',"comment":' + df_result_comment.T.to_json() + '}'
学習結果データのCSVファイル
学習結果データのCSVファイルは以下のようになる。最初の2行が拡張したコメント部分で、残りがデータ部分である。後の処理の都合上、できるだけ元データのCSVファイルと似た形式にしている。varの部分に,が入っているが、Python PandasやExcelでは問題なく処理される。CSVファイルをテキストで見ると、この部分は""で囲まれている。
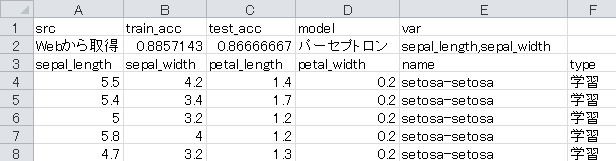
学習結果の表示
Pythonからのデータを受け取り、Javascriptで画面表示する。まずHTMLに画面表示する場所を記載する。学習データとテストデータを幅6の列に分けて、それぞれにコメントと画像ファイルを表示する。row・colの中にさらにrow・colがある2重構造になっている。
<div class="row">
<div class="col-sm-12 border border-info rounded py-2">
<div id="result-comment"></div>
<div class="row">
<div class="col-sm-6 py-2">
<div id="result-acc-train"></div>
<img id="result-image-train" class="img-fluid" src="">
</div>
<div class="col-sm-6 py-2">
<div id="result-acc-test"></div>
<img id="result-image-test" class="img-fluid" src="">
</div>
</div>
</div>
</div>
次にPythonを使って画像ファイルを表示する処理を作成する。resultディレクトリはFlask管理外にあるため、そのままではブラウザに表示できない。ダウンロードの場合と同様にsend_file関数を使う事で、画像ファイルにアクセスできる。HTMLのgetを使い、resultとtype(trainかtest)を指定する。
@app.route('/result-image')
def result_image():
result = request.args.get('result')
type = request.args.get('type')
return send_file('result/%s/%s.png' % (result, type))
次にJavascriptで以下の処理を行う。learn関数は前述したPythonとのデータ送受信処理である。ここでPythonから受け取ったJSONデータを変換し、writeResult関数を呼び出す。writeResult関数ではコメントを整形して、HTMLのresult-acc-trainとresult-acc-testに記載する。
画像ファイルを表示するため、HTMLのresult-image-trainとresult-image-testにあるsrc部分を修正する。?と&を使ったget構文で、前述のPython処理を呼び出している。コメントのようなhtml関数による修正でなく、imgのsrc部分だけを変更する。html関数を使うと、イメージを変更する際に一度画面が消えて見にくくなるためである。ver以降は毎回HTMLアドレスを変更して、ブラウザに画像を再読み込みさせるテクニックである。これは自分用のCSS・Javascriptファイルにおいて使ったテクニックと同じである。
最後のanimate関数はjQueryの機能で、ブラウザをスクロールさせるものである。これは最初の表示において画像ファイル全体を見せるために使っている。
function learn() {
$.post('/learn',$('#result-form').serialize())
.fail(function(ret) {
alert('学習に失敗しました');
})
.done(function(ret) {
let retParse = $.parseJSON(ret);
writeResult(retParse);
});
}
function writeResult(retParse) {
let comment = retParse.comment[0];
let commentStr = '元データ:' + comment.src + '、モデル:' + comment.model +
'、使用変数:' + comment.var;
$('#result-comment').html('<p>' + commentStr + '</p>');
$('#result-acc-train').html('学習正解率:' + comment.train_acc.toFixed(4));
$('#result-acc-test').html('テスト正解率:' + comment.test_acc.toFixed(4));
date = new Date();
var imgTrain = $('#result-image-train')[0];
var imgTest = $('#result-image-test')[0];
imgTrain.src = 'result-image?result=' + retParse.result + '&type=train&ver=' + date.getTime();
imgTest.src = 'result-image?result=' + retParse.result + '&type=test&ver=' + date.getTime();
$("html,body").animate({scrollTop:$('#result-comment').offset().top}, 'fast');
}
学習結果の表示内容は以下のようになる。