 AsaHP
AsaHP
深層学習のAttention・Transformer 技術の概要
Attentionは2014年頃から研究が始まった、比較的新しい技術である。2017年のTransformer(Attentionだけの機械翻訳)発表から広く用いられるようになった。現在では研究の主力となっている技術である。
一般的にはAttentionよりもTransformerの方が有名かもしれない。Transformerの使用例も多数あるが、Attentionの使用例はさらに多い。今までの深層学習はCNNとRNNが主体で、Attentionは補助的な技術だった。現在ではAttentionが最も研究されている。CNNは二次元データ、RNNは系列データという制約があるのに比べ、Attentionには制約がなく様々なデータに使える。
Attentionは翻訳・言語解析・画像キャプション・画像Q&Aなどで使われている。グラフ構造・時系列などの適用例や、確率モデルとする例もある。最近は高分子・有機化学でも大きな発展が見られる。Attentionを可視化すると判定根拠を見る事ができ、XAI(説明可能なAI)としても優れている。XAIは制御の容易さにも繋がる。Attentionを人間が変更する事で深層学習の性能を向上させる研究もある。
AttentionはニューラルチューリングマシンやGoogle翻訳など有名なモデルでも使用されている。
深層学習で良く使われるモデルにはSoft AttentionとHard Attentionがあり、特にSoft Attentionが多用される。
Attentionは幅広い分野で利用されているが、実装にはしっかりしたデータ構造が必要であるらしい。どんな分野にも簡単に使える、と言う訳ではなさそうである。
Attentionの構造
Attentionは「注意」という一般用語であり、人工知能・機械学習において様々な意味がある。Attentionは認知科学的な背景を持っている。情報の一部を「注意」する事で認知的な挙動ができるという考え方である。大きな処理の流れは以下のようになる。
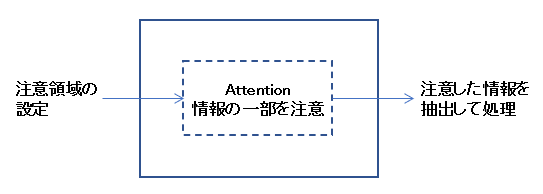
注意領域の設定は自動的に行われるが、部分的に人間が設定する場合もある。注意領域を可視化すれば、Attentionを使った処理において何を判定根拠としているか分かる。これによりXAI(説明可能なAI)としての能力を持つ。外部から注意領域を制御する事で、Attentionを使った処理の制御が可能になる。注意領域は人間が判別できるので、人間による制御も容易になる。これはハイパーパラメータチューニングなどでも有益である。
1つのAttentionだけでは複雑な処理ができないので、複数のAttentionを組み合わせる事が多い。Attentionの後ろにFFN(Feed Forward Network)を置いて多層化する手法が用いられる。またAttentionを横に並べるMulti-Head Attentionも重要で、これにより同時に複数の個所を「注意」する事ができる。
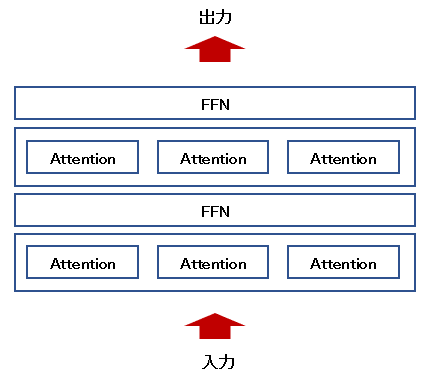
この方法は性能向上や並列化において有利である。AttentionはRNNと違い並列化が容易なので、それも現在の発展の一因と思われる。ただ複数の個所を注意するので説明可能性は低下する。
Soft Attention
最近の深層学習で有名なのはSoft Attentionという技術である。Soft Attentionの全体像については、以下のチュートリアルに詳しく載っている。
A Tutorial on Attention in Deep Learning [2019]
翻訳時の処理イメージを以下に示す。重み行列の作成と、それを使った出力計算に分かれる。keyが「注意」の対象となる情報になる。
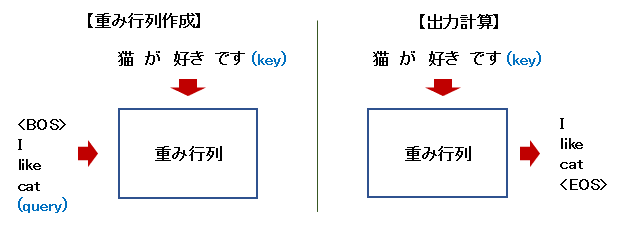
出力計算を数式で書くと以下のようになる。key $k$ と重み $w$ を使って出力 $o$ を計算する。 \[o_i = \sum_j w_{ij} k_j\] この時に、重み $w$ がkeyの重要性を示す指標になる。重みがkeyに対する「注意」の程度となり、注意領域を意味する。重みを可視化すると判定根拠が分かる。keyに対応する重みベクトルは出力単語ごとに存在し、出力単語ごとにkeyの一部を「注意」する事になる。
Soft Attentionと呼ぶのは、Attentionを重みの程度で計算する事による。Soft Attentionは微分が容易であり、それが深層学習で多用される理由になる。keyはmemoryと呼ばれる事もある。
key等の1単語ごとにベクトルが存在すため、実際の出力計算は行列積になる。
重み行列は、query $q$ とkey $k$ から何らかの関数 $f$ で計算される。翻訳時のqueryは、出力 $o$ を1単語前にずらしたものになる。 \[w_{ij} = f(q_i, k_j)\] 出力計算においてkeyの全体構造が反映される。重み行列の作成時には全体構造を見ておらず、それぞれの重みに反映されるのはqueryとkeyの1単語のみである。
Hard Attention
Hard Attentionは重みが0か1になり、特定のkeyを「選択」する動作になる。微分が難しいので、強化学習的な探索が必要になる。Soft Attentionより利用例は少ないが、Hard Attentionも使われる場合がある。Soft/Hardが明示されない場合も多く区別が難しい。
Transformer
GoogleがGNMTを改良した、非常に有名なモデルである。RNNを使わずにSoft Attentionだけで機械翻訳を実現した。
Attentionの重み計算に内積を使うDot-Product Attention [2015]を使用している。内積で消える次元は、1単語ごとのベクトルである。Additive Attentionより計算量が少なくて済む。内積だけだとうまく重み計算ができないので、様々な手法を組み合わせている。入出力時に単純なNNを入れるなどの方法により学習させている。
複数の小さなAttentionをアンサンブルするMulti-Head Attentionを導入している。通常のAttentionはkeyの1要素しか注目しないので、複数要素に注目させる方法として有効である。
Dot-Product AttentionよりもMulti-Head Attentionの方が重要である。Dot-Product Attentionは性能が向上する訳ではないが、Multi-Head Attentionは性能に直結するからである。
18個のMulti-Head Attentionを組み合わせる事で、queryやkeyの全体構造を高度に計算している。queryやkeyに対して自分自身のAttentionを計算するSelf-Attentionも活用している。下図の左下がkeyで、右下がqueryである。
Attention Is All You Need [2017]
Transformerの内部構造については以下のページが詳しい。
作って理解する Transformer / Attention
このページにはサンプルも付いている。3:コードのページも参照のこと。
目次
技術の概要
著名な論文と各分野の論文
サンプルコード・論文のコード