 AsaHP
AsaHP
怺憌妛廗偺Attention丒Transformer 挊柤側榑暥偲奺暘栰偺榑暥
Attention偵娭偡傞挊柤側榑暥偲丄條乆側暘栰偺榑暥偵偮偄偰傑偲傔偨丅摿偵斈梡惈偵拲栚偟偰偄傞丅
Transformer偵偮偄偰偼奣梫傪嶲徠丅
埲壓乽Attention乿偲偁傞偺偼丄摿偵婰嵹偑側偄尷傝Soft Attention偱偁傞丅
僯儏乕儔儖僠儏乕儕儞僌儅僔儞
NN偱僠儏乕儕儞僌儅僔儞傪幚憰偟偨傕偺偱偁傞丅僐僺乕傗僜乕僩側偳偺扨弮側傾儖僑儕僘儉傪悇榑偱偒傞丅AlphaGo偱桳柤側DeepMind幮偑嶌惉偟偨丅偙偪傜偺曽偑東栿側偳傛傝愭偵幚憰偝傟偨傛偆偱偁傞丅Memory偺撉傒彂偒偵偍偄偰Attention傪巊偭偰偄傞丅Memory偼慜弎偺key偵憡摉偡傞丅Controller偼RNN傗FFN乮Feed Forward Network乯傪巊偭偰偄傞丅
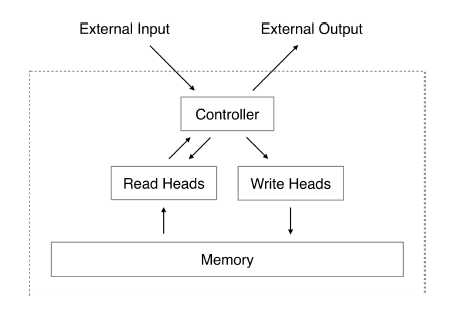
Neural Turing Machines [2014]
忋婰偺峔憿偼擣抦壢妛揑側攚宨傪帩偭偰偄傞丅Memory偺堦晹傪乽拲堄乿偡傞帠偱擣抦揑側嫇摦偑偱偒傞偲偄偆峫偊曽偱偁傞丅暿偺榑暥偱偼丄Attention傪巊傢偢偵Memory傪埖偆庤朄傪専摙偟偰偄傞応崌傕偁傞丅
Google's Neural Machine Translation System
2016擭偺Google東栿偵幚憰偝傟偨儌僨儖偱丄偦傟埲慜偺婡夿東栿偐傜奿抜偵恑曕偟偨丅RNN乮LSTM乯偲Attention傪暪梡偟丄GPU側偳條乆側媄弍傪廤栺偟偰幚尰偟偰偄傞丅偙偙偱偺Attention偼Additive Attention [2014]偲屇偽傟傞傕偺偱丄Attention偺廳傒傪娙扨側FFN偱寁嶼偡傞丅偙偺曽朄偩偲FFN偱寁嶼偡傞僨乕僞検偑懡偄偲偄偆栤戣偑偁傞丅
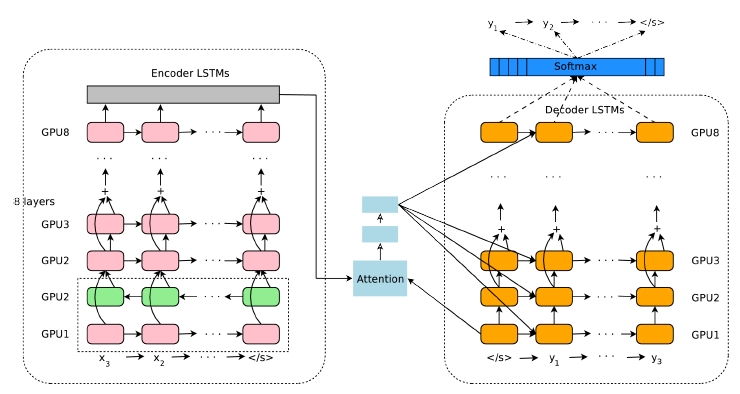
Google's Neural Machine Translation System [2016]
BERT
Google偑Transformer偺婯柾傪奼戝偟偰嶌惉偟偨丄尵岅張棟僣乕儖偱偁傞丅暋暥乮Q&A側偳乯傪妛廗偝偣傞帠偱丄暋暥偺夝摎偩偗偱側偔扨岅偺庬暿敾掕側偳傕偱偒傞丅妛廗嵪傒儌僨儖偑岞奐偝傟偰偍傝丄棙梡幰偼偦傟傪巊偭偰AI傪峔抸偱偒傞丅妛廗嵪傒偺BERT偵條乆側彫偝偄儗僀儎乕傪捛壛偡傞帠偱丄Q&A傗扨岅庬暿敾掕側偳傪巊偄暘偗傞帠偑偱偒傞丅
Transformer傛傝懡偔偺Attention傪慻傒崌傢偣傞帠偱丄query傗key偺慡懱峔憿傪崅搙偵寁嶼偟偰偄傞丅擖椡僨乕僞偺儅僗僋側偳傪巊偄妛廗傪岺晇偟偰偄傞丅

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [2018]
尵岅張棟
T5偼Google偑嶌惉偟偨儌僨儖偱丄Transformer傪懡偔偺僞僗僋偵懳墳偱偒傞傛偆偵偟偨丅東栿側偳偺暋悢偺僞僗僋傪丄偡傋偰幙栤偲夞摎偲偄偆宍幃偱張棟偟偰偄傞丅C4偲偄偆嫄戝側僨乕僞僙僢僩傪巊偭偰偍傝丄偙傟偼Web偐傜僋儘乕儖偟偨僨乕僞傪尦偵嶌惉偟偨傕偺偱偁傞丅
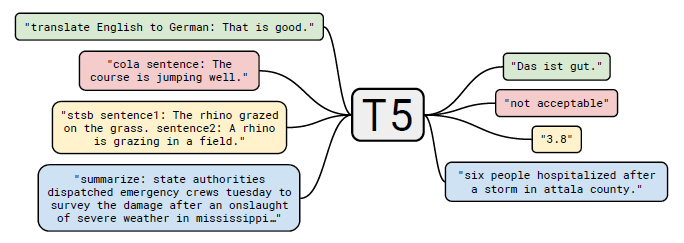
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer [2019]
GPT-3偼Open AI偑奐敪偟偨丄BERT傪偝傜偵戝婯柾壔偟偨尵岅僣乕儖偱偁傞丅嫄戝僨乕僞僙僢僩偲嫄戝僱僢僩儚乕僋傪巊偭偨帠慜妛廗偑摿挜偱偁傞丅偙傟偵娙扨側捛壛妛廗傪峴偆帠偱丄東栿丒幙栤墳摎丒僯儏乕僗惗惉側偳偺張棟偑偱偒傞丅BERT偲摨條偵棙梡幰偼帠慜妛廗嵪傒偺儌僨儖傪棙梡偱偒傞丅抍懱柤偵Open偲晅偄偰偄傞偑姰慡偵僆乕僾儞偱偼側偔丄棙梡幰偼抍懱丒婇嬈偵怽惪偟偰棙梡偡傞宍偱偁傞丅Open AI偺API傗丄Microsoft惢昳偐傜棙梡偱偒傞丅
偲偵偐偔戝婯柾側偺偑摿挜偱偁傝丄嵟戝偺儌僨儖偵側傞偲BERT偲斾傋偰傕悢昐攞偺憤妛廗帪娫偑偐偐傞丅偨偩偟戝敿偼帠慜妛廗偱丄棙梡帪偺妛廗帪娫偼彮側偄偲巚傢傟傞丅
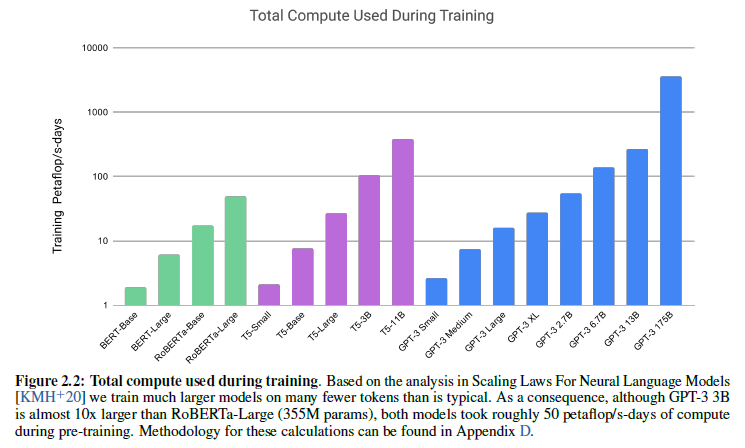
Language Models are Few-Shot Learners [2020]
夋憸僉儍僾僔儑儞
Attention偼夋憸僉儍僾僔儑儞偱傕傛偔梡偄傜傟偰偄傞丅CNN偵傛傞夋憸摿挜拪弌偲丄Attention傗RNN偵傛傞尵岅張棟傪慻傒崌傢偣傞帠偱幚尰偱偒傞丅

怺憌妛廗傪梡偄偨夋憸傪愢柧偡傞暥惗惉庤朄偺堦峫嶡 [2016]
夋憸Q&A
夋憸僉儍僾僔儑儞偺墑挿偲偟偰丄夋憸偵幙栤傪壛偊偰夞摎傪摼傞張棟偑偁傞丅Reasoning偲傕屇偽傟傞丅
師偺椺偼Attention傪2偮嶌傝丄夋憸Q&A偲夋憸亄暥偺堦抳昡壙傪摨帪偵峴偆傕偺偱偁傞丅
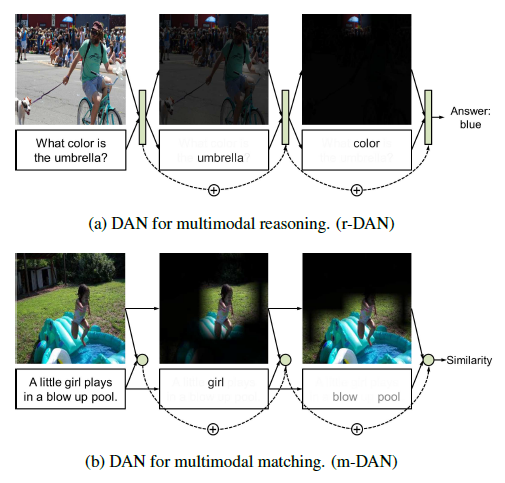
Dual Attention Networks for Multimodal Reasoning and Matching [2016]
師偺椺偼Attention傪巊偭偰Control偲Memory傪帩偮暋崌揑側僔僗僥儉傪嶌傝丄夋憸Q&A傪張棟偡傞傕偺偱偁傞丅Control偲Memory偺峔憿偼僯儏乕儔儖僠儏乕儕儞僌儅僔儞偵嬤偄丅

Compositional Attention Networks for Machine Reasoning [2018]
師偺椺偼Hard Attention偵傛傞夋憸Q&A偱偁傞丅旝暘晄擻偺栤戣偼丄Hard Attention偺慖戰椞堟傪摿挜検偺戝偒偄強偵偟偰夞旔偟偰偄傞傜偟偄丅

Learning Visual Question Answering by Bootstrapping Hard Attention [2018]
僌儔僼峔憿
師偺椺偼Attention偱僌儔僼峔憿傪張棟偡傞傕偺偱偁傞丅Attention偺堦晹偵儅僗僋傪擖傟傞帠偱僌儔僼峔憿傪昞尰偟偰偄傞丅儅僗僋偼嬤朤僲乕僪傪巆偡傛偆偵屌掕揑偵擖傟傞丅Additive Attention偲Multi-Head Attention傪巊梡偟偰偄傞丅壓恾偺慄偺懢偝偑Attention偺戝偒偝偱偁傞丅
Graph Attention Networks [2017]
師偺椺偼忋婰偺儌僨儖GATs傪僫儗僢僕僌儔僼偵墳梡偟偨傕偺偱偁傞丅GATs偱偼僄僢僕偺娭學忣曬偑側偄偺偱丄偙傟傪Attention偱慻傒崬傫偱偄傞丅
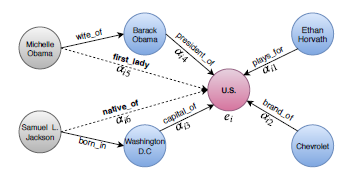
Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs [2019]
崅暘巕丒桳婡壔妛
師偺椺偼DeepMind幮偑嶌惉偟偨丄AlphaFold2偲屇偽傟傞僞儞僷僋幙愜傝忯傒梊應偱偁傞丅崅懍偐偮崅惛搙偺梊應偑偱偒傞傛偆偵側傝嵟嬤榖戣偵側偭偰偄傞丅
Transformer偵暘巕恑壔偺忣曬傪慻傒崬傫偩Evoformer偲偄偆庤朄偵摿挜偑偁傞丅埲壓偺恾偼Evoformer偺拞妀晹暘偱偁傞丅儁傾昞尰偐傜廳梫晹暘傪庢傝弌偟偨僌儔僼峔憿偵懳偟丄嶰妏宍偺晹暘偱峏怴寁嶼傪峴偭偰偄傞丅嶰妏宍偺忔嶼寁嶼傪2夞丄self-attention傪2夞峴偭偰傞丅
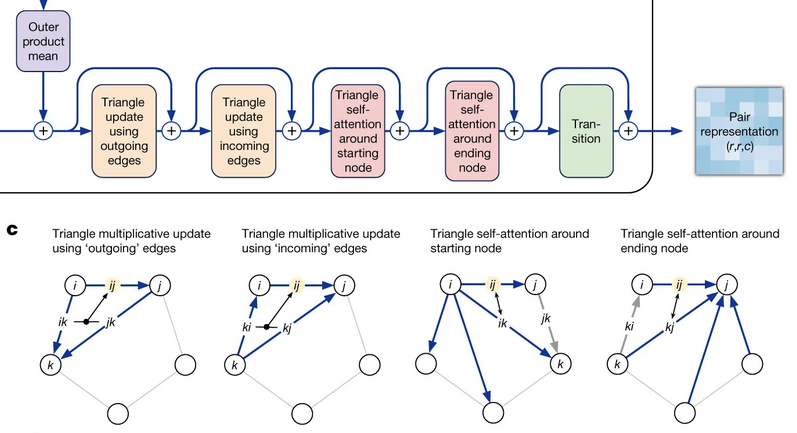
尦榑暥偲丄偦偺擔杮岅夝愢婰帠傪埲壓偵帵偡丅
Highly accurate protein structure prediction with AlphaFold [2021]
僗僢僉儕傢偐傞AlphaFold2
懠偺擔杮岅婰帠傪埲壓偵帵偡丅
乽AlphaFold2乿偺徴寕2 ITmedia
AlphaFold2偵傛傝妀枌岴暋崌懱偺棫懱峔憿偑敾柧 AI-SCHOLAR
師偺椺偼桳婡壔妛崌惉偱偁傞丅壔妛幃傪尵岅壔偟偰Transformer偵擖傟偰偄傞丅

Molecular Transformer - A Model for Uncertainty-Calibrated Chemical Reaction Prediction [2018]
帪宯楍
Attention偼帪宯楍偵懳偟偰傕揔梡椺偑偁傞丅埲壓偺儁乕僕偵婔偮偐偺椺偑嵹偭偰偄傞丅惈擻揑偵偼崅偄傕偺偺丄巊偄彑庤偺埆偝偐傜堦斒揑偵巊梡偝傟偰偄側偄丄偲寢榑晅偗偰偄傞丅
Attention for time series forecasting and classification
忋婰偺儁乕僕偵偁傞椺偺堦偮傪庢傝忋偘傞丅Transformer偲忯傒崬傒偵傛傝嬊強揑側嫇摦傪拪弌偱偒傞傛偆偵偟偰偄傞丅僨乕僞検偑朿戝偵側傞偲偄偆栤戣偵懳偟丄摿掕偺婯懃偱棧嶶揑偵僨乕僞傪廍偆帠偱懳墳偟偰偄傞丅1僨乕僞偛偲偺儀僋僩儖偲偟偰丄捈慜帪娫偺抣偲丄奺庬廃婜偵偍偗傞抣傪巊偭偰偄傞丅寢壥傪RNN傪巊偭偨DeepAR傗DeepState偲斾傋偰偄傞丅

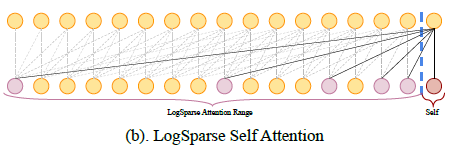
Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting [2019]
妋棪儌僨儖
師偺椺偼忦審晅偒妋棪応傪巊偭偰丄栘峔憿偺曄姺傗帺慠尵岅張棟傪峴偆傕偺偱偁傞丅忦審晅偒妋棪応偼柍岦僌儔僼偱昞尰偱偒傞妋棪儌僨儖偱偁傞丅柍岦僌儔僼偺埶懚娭學傪帩偮妋棪曄悢偵懳偟偰丄忦審晅偒妋棪傪嵟戝壔偡傞丅Attention偺暘晍偵懳偟偰忦審晅偒妋棪応傪摫擖偟偰偄傞丅捠忢偺Soft Attention埲奜偺埶懚娭學傪巊偭偰張棟傪偟偰偄傞丅
Soft Attention偵偍偗傞弌椡寁嶼偺悢幃傪丄曄悢傪曄偊偰嵞宖偡傞丅key $x$ 偲廳傒 $w$ 傪巊偭偰弌椡 $o$ 傪寁嶼偡傞丅 \[o_i = \sum_j w_{ij} x_j\] 偙偺 $w$ 傪旕晧偵尷掕偟偰丄埲壓偺忦審傪晅偗傞丅 \[\sum_j w_{ij} = 1\] 偙偆偡傞偲丄弌椡寁嶼偺幃偼廳傒傪妋棪偲偡傞婜懸抣偺幃偲尒側偣傞丅廳傒偺埵抲傪帵偡愽嵼曄悢傪 $z$ 偲偡傞丅Soft Attention偱偺 $z$ 偼key偺捠斣 $j$ 偱偁傝丄1屄偺曄悢偵側傞丅偙傟偑壓恾((a))偺峔憿偱偁傞丅
((b))埲崀偼Soft Attention埲奜偺埶懚娭學傪帵偡丅((b))偼 $z$ 偑 $x$ 偵懳墳偡傞儀僋僩儖偱丄儔儞僟儉偵 0 or 1 偺抣傪帩偮応崌偱偁傞丅偙偺応崌偺妋棪偼儀儖僰乕僀暘晍偵側傞丅((c))偼 $z$ 偺儀僋僩儖偑慄宍偺娭學傪帩偮応崌偱偁傞丅
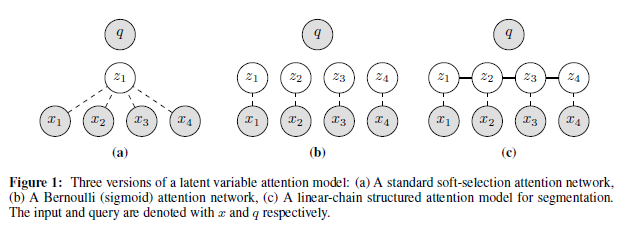
STRUCTURED ATTENTION NETWORKS [2017]
Attention偺愱栧壠偵傛傞廋惓
師偺椺偼丄Attention傪愱栧壠偑廋惓偡傞帠偱夋憸敾暿偺惈擻傪岦忋偝偣傞庤朄偱偁傞丅

僄僉僗僷乕僩偺抦尒傪庢傝擖傟偨儅儖僠僗働乕儖丒傾僥儞僔儑儞婡峔偵傛傞幘姵幆暿 [2020]
偦偺懠
師偺椺偼丄Capsule Networks偁傞偄偼CapsNets偲屇偽傟傞庤朄偵懳偡傞Attention偺幚憰椺偱偁傞丅CapsNets偼彫斖埻偺夋憸偺摿挜偱偁傞乽僇僾僙儖乿傪宷偘偰慡懱傪昞尰偡傞傕偺偱丄CNN傪戙懼偡傞庤朄偱偁傞丅偙偺僇僾僙儖傪宷偘傞晹暘偵Attention傪巊偭偰偄傞丅

Capsules with Inverted Dot-Product Attention Routing [2019]
栚師
媄弍偺奣梫
挊柤側榑暥偲奺暘栰偺榑暥
僒儞僾儖僐乕僪丒榑暥偺僐乕僪